Utiliser des regex pour résoudre SUTOM
Les regex
En informatique, il existe ce que l’on appelle des Regex, contraction de regular expression en anglais. En français on parle d’expressions régulières ou rationnelles. Les regex sont issues de théories mathématiques et ont été créées initialement pour décrire des langages formels (ensemble de mots). A ce moment-là on est aux prémices de l’informatique moderne.
Aujourd’hui les regex sont utilisées un peu partout. On en retrouve au niveau des compilateurs et des interprètes notamment, mais aussi par exemple au niveau des champs de formulaires. Cela permet de réaliser des contrôles sur les entrées faites par un utilisateur. Un exemple qui illustre bien cela : vérifier que la complexité d’un mot de passe lors de sa création ou modification respecte la politique de sécurité mise en place par l’administrateur.
C’est justement cette application qui nous intéresse. En appliquant des regex sur des chaines de caractères, on obtient de puissants outils de filtrage.
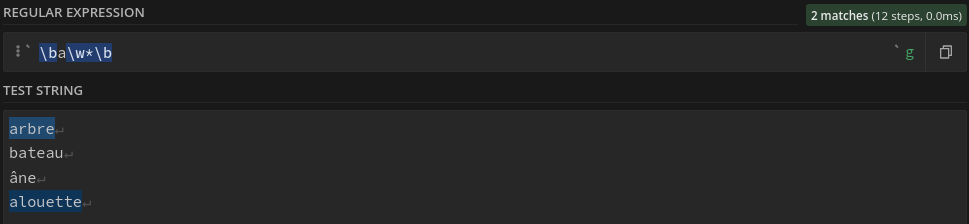
Une expression régulière peut être simple :
\ba\w*\b
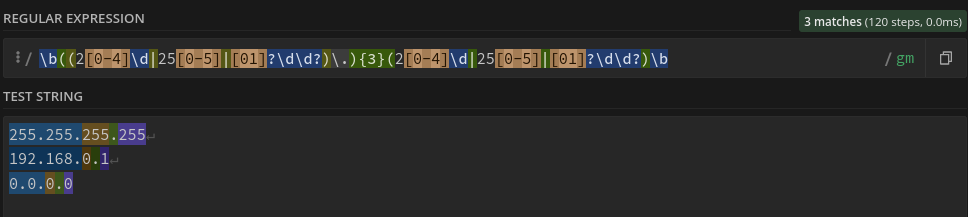
ou plus compliquée :
\b((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)\b
C’est pour cela que l’on a tendance à les “oublier”.
Une regex est constituée de motifs dont la syntaxe est très riche. Je vais lister les plus courants :
Méta-caractères
| Caractères | Description |
|---|---|
| . | Remplace tout caractère |
| * | Remplace une chaîne de 0,1 ou plusieurs caractères |
| ? | Remplace exactement un caractère |
| () | Groupe capturant |
| [] | Intervalle de caractère |
| {} | Quantificateur |
| \ | Déspécialise le caractère spécial qu’il précède |
| ^ | Négation ou début de ligne |
| $ | Fin de ligne |
| | | Ou logique entre 2 sous-motifs |
| + | Numérateur |
Répétitions
| Caractères | Description |
|---|---|
| * | Répète un nombre de fois quelconque |
| + | Répète au moins une fois |
| ? | Répète zéro ou une fois |
| {n} | Répète n fois |
| {n,m} | Répète entre n et m fois |
| {n,} | Répète au minimum n fois |
Frontières de recherche
| Caractères | Description |
|---|---|
| ^ | Début de ligne |
| $ | Fin de ligne |
| \b | Extrémité de mot |
| \B | Extrémité d’un non-mot |
| \A | Début de la chaîne soumise |
| \G | Fin de l’occurrence précédente |
| \Z | Fin de la chaîne soumise, à l’exclusion du caractère final |
| \z | Fin de la chaîne |
Classe de caractères
| Caractères | Description |
|---|---|
| \d | Une chiffre, équivalent à [0-9] |
| \D | Un non-chiffre, [^0-9] |
| \s | Un caractère blanc, [\t\n\x0B\f\r] |
| \S | Un non-caractère blanc, [^\s] |
| \w | Un caractère de mot, [a-zA-Z_0-9] |
| \W | Un caractère de non-mot, [^\w] |
| . | Tout caractère |
Donc si l’on reprend mes exemple précédents :
\ba\w*\b
recherche tous les mots commençant par la lettre a
\b((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)\b
recherche 3 séquences de 1 à 3 digits terminés par “.” suivi d’une autre expression de 1 à 3 digits. Chacune de ces séquence n’excède pas 255. Cette regex permet donc de capturer des adresses IP.
Screenshots provenant de l’excellent site regex101 que je recommande vivement pour tester ses regex.
Mais comment appliquer cela au jeu Sutom ?
Sutom
Sutom est un jeu devenu viral. Le principe est simple : un mot entre 6 et 9 lettres est à deviner. Le joueur dispose de la première lettre du mot à deviner, de sa longueur, et de 6 essais. A chaque essai :
- les lettres bien placées sont entourées d’un carré rouge,
- celles mal-placées d’un rond jaune,
- les lettres restant sur le fond bleu ne font pas parti du mot à deviner.
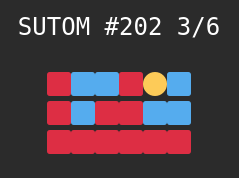
Prenons un exemple avec le mot à trouver du 28 juillet 2022 :

J’ai fait un premier essai avec le mot SIGNAL et j’ai obtenu les indications suivantes :
-
S et N sont bien placés
-
A est mal placé mais présent
-
I, G et L sont exclus (grisés sur le clavier)
D’essais en essais on accumule des informations sur la présence ou non présence des lettres et sur leur position.
Trouver le mot du jour avec des regex
On arrive au sujet principal de ce billet. Lorsqu’un humain joue à Sutom, il fait appel à :
-
son vocabulaire
-
sa logique.
Cela tombe bien car un ordinateur peut avoir les deux. Avec un dictionnaire on lui donne le vocabulaire. Quant à la logique, on peut lui apprendre. C’est là qu’interviennent nos regex.
Pour trouver le mot du jour, il faudrait donc donner à notre ordinateur une regex assez puissante pour filtrer dans un dictionnaire et nous donner des résultats à partir des informations données par le jeu. Une telle regex devrait en théorie pouvoir trouver le mot en 3 ou 4 essais.
Reprenons notre exemple du 28 juillet. Nous avons un mot de 6 lettres qui commence par un S.
Pour filtrer les mots de 6 lettres commençant par S il faut utiliser la regex suivante :
\bs.{5}\b
Rappelez-vous la première partie du billet :
-
\b indique l’extrémité d’un mot,
-
le . qu’il s’agit de n’importe quel caractère
-
le {5} que le caractère précédent est répété exactement 5 fois.
Mon programme trouve 1003 mots dans le dictionnaire qui sont matchés par cette regex.
Parmi ces 1003 mots, j’ai essayé SIGNAL. On obtient alors de nouvelles informations que l’on peut donner au programme :
-
le N est bien placé
-
le A fait parti du mot mais n’est pas à la bonne position
-
les lettres I, G et L ne sont pas présentes dans ce mot

Transcrivons ces informations sous la forme d’une nouvelle regex. Nous allons construire la regex en plusieurs étapes.
→ Nous cherchons les mots qui contiennent un A
Pour capturer cela on va utiliser une assertion positive (ou positive lookahead). L’assertion positive permet dire “je veux un A après le S”. L’assertion positive a la forme (?=REGEX).
Une regex dans une regex, oui oui.
Nous cherchons n’importe quel caractère (rappelez-vous c’est le ‘.’) suivi d’un A.
(?=.*a)
Si l’on reprend, à ce stade notre regex a la forme suivante :
\b(?=.*a)s.{5}\b
Les assertions servent à matcher des patterns. Elles renvoient simplement True ou False si elles trouvent le pattern.
→ Maintenant il nous faut éliminer les mots contenant lettres I, G ou L.
Pour filtrer ces mots, on va utiliser une assertion négative. Cette dernière a la forme (?!REGEX). Si la REGEX à l’intérieur de l’assertion retourne TRUE, alors l’assertion retourne FALSE. Intuitif non ?
(?!.*[igl])
Concaténons cette assertion avec le reste :
\b(?=.*a)(?!.*[igl])s.{5}\b
→ Enfin n’oublions pas une information importante, la position du N est correcte.
Nous obtenons alors une regex finale :
\b(?=.*a)(?!.*[igl])s..n..\b
Si on la résume sommairement :
-
S
-
on veut un A
-
on ne veut pas de I, G, L
-
on revient après le S, on met deux lettres n’importe lesquelles
-
on met un N
-
on met deux lettres n’importe lesquelles
Cette regex me permet d’obtenir une liste de seulement 18 mots candidats. Pas mal mais c’est encore trop pour trouver notre mot.
Essayons un nouveau mot au hasard à partir de la liste qui nous est retournée : STANDS.

Ce coup-ci le A est bien positionné et nous pouvons éliminer les lettres T et D.
\b(?!.*[igltd])s.an..
La liste se réduit à 1 possibilité. C’est notre mot. “Sutom !” :)
Comme on le voit les regex sont des outils bien pratiques. 3 essais au Sutom sont considérés comme un bon score.
J’ai utilisé le dictionnaire qui est fourni par ma distribution : “/usr/share/dict/french”
J’ai des raisons de penser que ce dictionnaire n’est pas le même que celui utilisé par le jeu. Lors de la rédaction de ce billet un mot du jour était BALAISE. Or le dictionnaire de mon programme ne connait que l’orthographe BALEZE.
Pour être vraiment efficace, il faudrait utiliser le même que le jeu. Je mets les sources à dispo sur mon Github pour ceux qui veulent tester.
Note de fin
Le programme marche également avec Wordle. Le principe est le même que SUTOM mais il y a quelques variations. La longueur du mot à deviner est fixe et on ne connait pas la première lettre.
Avec ces paramètres, les regex sont moins efficaces que sur Sutom. Le mot est trouvé plutôt aux alentours du 5ème ou du 6ème essai.
Ce comportement est normal puisque sans le filtre de la première lettre, on a beaucoup plus de mots qui sont matchés par les regex. Une amélioration du programme pourrait être de proposer des mots avantageux en terme d’informations récupérées. Je pense notamment au dictionnaire présent sur le site Lexique qui donne les fréquences d’occurrences.
Peut-être dans une v2 ;)